
[형베시] Project 2 - Milestone 2 Index Manager (On Disk B+tree) (1) struct, find, scan
귀찮음을 이겨내고 쓰는 두 번째 형베시 과제 정리 포스트.
개인적으로 글쓴이가 형베시 과제 중 가장 중요하다고 생각하는 부분이다.
왜냐하면 여기를 잘 하면 project3, project4까지 순조로워질 수 있다. 프젝5는 아니다
근데 얘를 잘 못하면 한 학기를 가시밭길 위로 riding하게 된다. 제가 riding함
프젝 2를 날려먹는다고 바로 F가 떠버리거나 하지 않는다. 뒤에 과제와 시험으로 성적은 어떻게 잘 만회할 수는 있다. 하지만 뒤 과제를 하기 위해선 프젝2가 완벽하게 동작을 해야하는데 남들이 프젝 3하고 있을 때 프젝 2를 완벽하게 고치고 과제 진도를 따라가야 하므로 뒤가 많이 고되진다…
아무튼 시작
Index Manager
Index란 key(search key)를 이용해서 DB에서 record를 빨리 찾을 수 있게 해주는 자료구조이다. 강의 자료에는 Index로 사용되는 자료구조가 B+ tree, Hash, R-Tree 등이 있다고 써있었는데, 수업 시간에는 ISAM과 B+tree를 위주로 배웠었다.
ISAM
ISAM(Indexed Sequential Access Method)은 structure modification이 일어나지 않는 트리 구조이다. 즉, insert, delete시에 트리의 구조가 변하지 않으며 order 개념이 없다. 만약 insert시에 overflow가 발생하여 해당 레코드를 넣을 수가 없게 되면 그 레코드는 overflow page에 순서 상관 없이 저장이 된다. Structure modification이 발생하지 않기 때문에 B+tree에 비해 concurrency control이 쉽고 구조와 구현이 단순하다는 장점이 있지만, 레코드에 접근할때 overflow page를 탐색해야하는 경우가 생길 수 있어 비효율적일 수 있다.
아래는 ISAM의 구조. (출처: https://courses.cs.washington.edu/courses/csep544/99au/lectures/class8/sld014.htm)
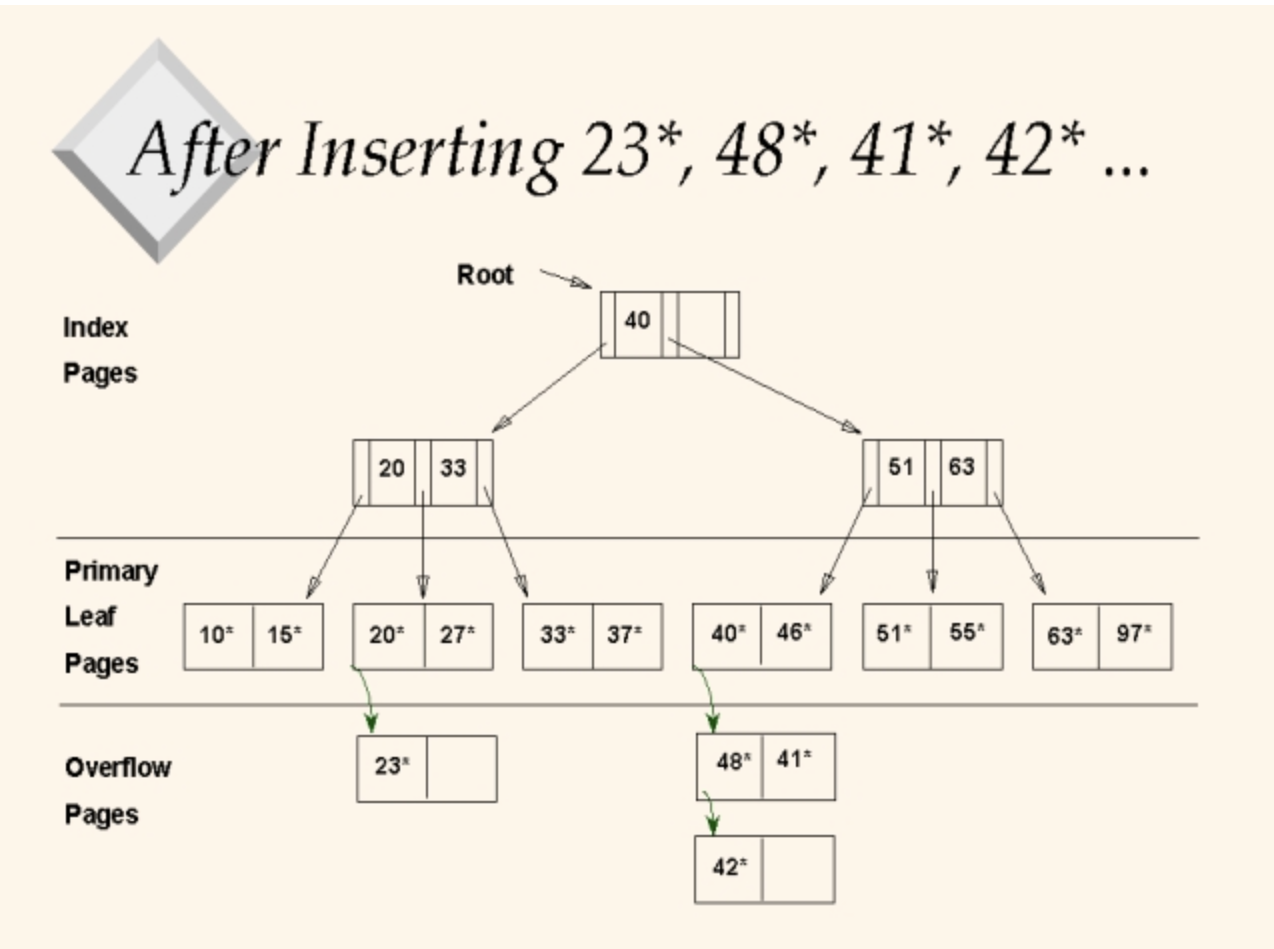
B+ tree
B+ tree는 insert시에 overflow가 발생하면 page의 split이 발생하고, delete시에 page의 merge가 발생할 수 있다. 즉, ISAM과 다르게 structure modification이 발생한다. overflow page가 없기 때문에 레코드에 접근하는 시간이 단축될 수 있지만, leaf page가 split되거나 merge되면 위에 internal page, 최악의 경우 root page까지도 변형이 일어날 수 있기 때문에 Concurrency control이 어려워진다.
B+tree는 이렇게 생겼다.
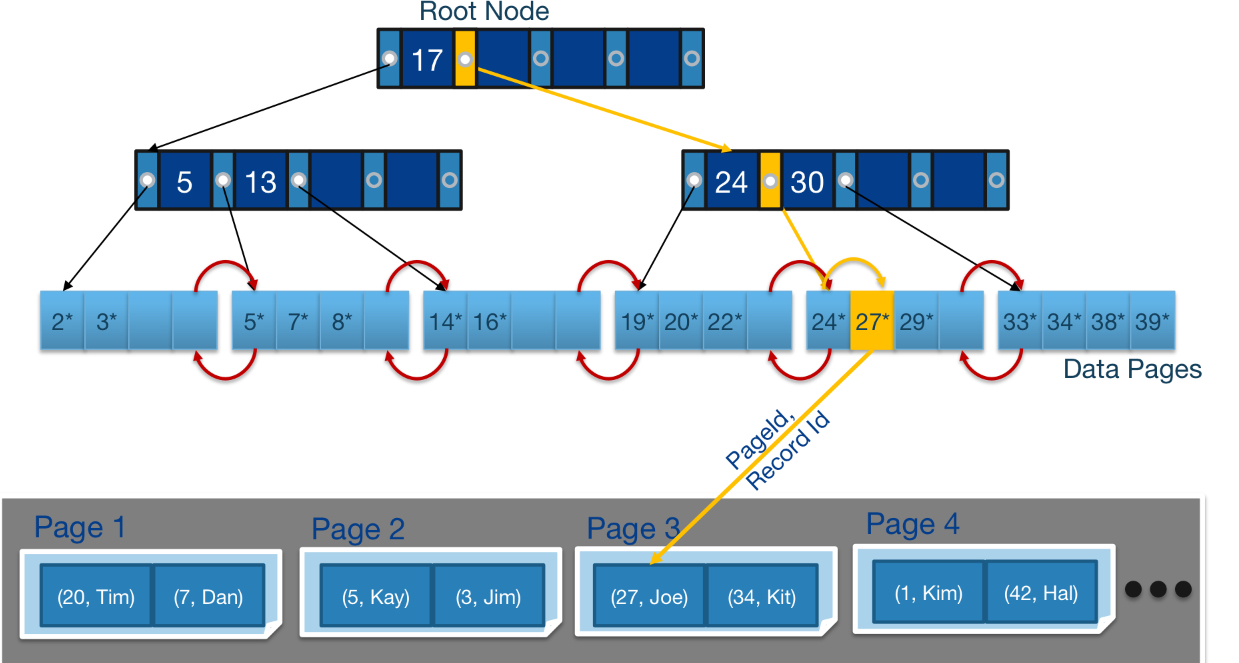
On Disk B+ tree의 구현
structs
과제 명세에서 준 leaf page의 모습은 이렇다.

프젝 2 마일스톤 1에서 page_t라는 기본 페이지 struct를 정의했었는데, 그걸 가만히 두고 leaf_page_t라는 새로운 struct를 정의하였다. value의 사이즈가 50 ~ 112 byte이기 때문에 value size에 따라서 한 페이지에 들어갈 수 있는 record의 개수가 달라지게 된다. 모든 value의 사이즈가 50이라면 slot은 최대 64개, 모든 value의 사이즈가 112라면 slot은 최대 32개가 된다. 따라서 slot의 최대 개수인 64개만큼의 배열을 선언해놓고, value가 들어갈 수 있는 value_space를 3200 byte만큼 선언해주었다. 만약 value의 사이즈가 커서 3200 byte를 넘어가게 되면 slot 배열 아래부분을 value 바이트 단위로 덮어쓰도록 했다.
typedef struct header_t {
/*
if the page is a free page, this field means next free page number.
if the page is an internal page or a lead page, this field means parent page number.
*/
pagenum_t next_free_page; //If the page is allocated. it is the parent page.
int is_leaf; // 0: internal or root, 1: leaf
int num_of_keys;
} header_t;
// ...
/*leaf node*/
typedef struct slot_t {
pagenum_t key;
uint16_t size;
uint16_t offset;
} slot_t;
typedef struct leaf_page_t {
header_t header;
char reserved_data[96];
pagenum_t amount_of_free_space;
pagenum_t right_sibling;
slot_t slots[64]; // # of slots : 32 ~ 64.
char value_space[3200]; // if there's no value space, I'll expand 112 bytes.
} leaf_page_t;
과제 명세에서 준 internal page는 다음과 같다.

/*internal node*/
typedef struct branch_factor_t {
pagenum_t key;
pagenum_t page_num;
} branch_factor_t;
typedef struct internal_page_t {
header_t header;
char reserved[104];
pagenum_t leftmost_index;
branch_factor_t branch_factors[248];
} internal_page_t;
만약 이렇게 선언하고 구조체의 바이트 수를 찍었을 때, 4096보다 크다면 패딩이 들어간 것이므로 패딩을 제거해주면 된다. 컴파일러에 따라 다른 것 같긴한데, 변수에 접근을 빠르게 하기 위해 4 bytes 단위로 맞추려고 패딩을 넣는 것 같다. 예를 들면 구조체 안에 char arr[3]; 이렇게 선언하였다면 3바이트 배열이지만 실제로는 4 bytes 차지하고 있을 것이다.
typedef struct slot_t {
pagenum_t key;
uint16_t size;
uint16_t offset;
} slot_t;
slot에 2 bytes짜리 변수가 2개 있는데, 얘네가 패딩이 들어가서 각각 4바이트가 되었는지 과제를 할 때 leaf page의 크기를 찍어보면 4096보다 크게 나왔던 것 같다. 다른 사람은 안 그랬던거 같은데 왜 나만 그랬지.. 아무튼 패딩을 없애주는 방법은 다음과 같다.
#pragma pack (push, 1)
//패딩을 없애주고 싶은 구조체를 이 부분에 정의
#pragma pack(pop)
#pragma pack (push, 1), #pragma pack(pop) 이 두 코드 사이에 구조체를 정의해주면 패딩을 빼고 내가 의도한 만큼의 크기로 저장된다.
APIs
이번 과제에서 구현해야할 api들은 다음과 같다.
int db_insert(int64_t table_id, int64_t key, const char *value, uint16_t val_size);
int db_find(int64_t table_id, int64_t key, char *ret_val, uint16_t *val_size);
int db_delete(int64_t table_id, int64_t key);
int init_db();
int shutdown_db();
int db_scan(int64_t table_id, int64_t begin_key, int64_t end_key,
std::vector<int64_t> *keys, std::vector<char *> *values, std::vector<uint16_t> *val_sizes);
insert, delete가 구현하기 너무 빡셌고 그게 진짜 이번 과제의 전부이다..
이번 포스트에서는 db_find, db_scan에 대한 설명만 싣고 insert, delete는 다른 포스트로 각각 분리해서 적어보려고 한다.
int db_find(int64_t table_id, int64_t key, char *ret_val, uint16_t *val_size)
table_id, key를 파라미터로 전달 받고 해당 record가 존재하면 ret_val에 value값을, val_size에 value의 길이를 저장하고 0을 리턴한다. 찾지 못한 경우에는 0이 아닌 값을 리턴한다. (여기서는 -1로 했다.) find 과정은
- ‘find_leaf’라는 함수를 만들어서 해당 key가 있을 페이지를 찾는다. 페이지 자체를 찾지 못했다면 root 조차 존재하지 않는 것이고, leaf page를 찾았더라도 그 안에 해당 key가 존재할지는 모른다.
- 찾은 leaf page의 slot 배열을 순차 탐색하면서 key가 있는지 확인한다.
- 끝까지 돌았을 때 찾지 못했다면 -1을 리턴, 찾았다면 해당 값과 길이를 저장하고 0을 리턴한다.
int db_find(int64_t table_id, int64_t key, char *ret_val, uint16_t *val_size)
{
pagenum_t root_num = bpt::get_root_num(table_id);
int i = 0;
pagenum_t leaf_num = bpt::find_leaf(table_id, root_num, key);
if (!leaf_num)
{
return FAIL; // there's no root
}
leaf_page_t leaf_page;
file_read_page(table_id, leaf_num, (page_t *)&leaf_page);
header_t leaf_header;
file_read_page_header((page_t *)&leaf_page, &leaf_header);
int num_of_keys = leaf_header.num_of_keys;
int idx;
for (idx = 0; idx < num_of_keys; idx++)
{
if (leaf_page.slots[idx].key == key)
{
break;
}
}
if (idx == num_of_keys)
{ // there's no target key
return FAIL;
}
else
{
int offset = leaf_page.slots[idx].offset;
memcpy(ret_val, ((char*)&leaf_page) + offset, leaf_page.slots[idx].size);
*val_size = leaf_page.slots[idx].size;
return 0;
}
}
find_leaf 함수는 다음과 같다. 이 함수는 mybpt.cc 파일에 bpt라는 namespace를 만들어 거기에 정의했다.
/*find function*/
pagenum_t find_leaf(int64_t table_id, pagenum_t root, int64_t key)
{
internal_page_t c;
pagenum_t next;
if (!root)
{ // there's no root
return 0;
}
file_read_page(table_id, root, (page_t *)&c);
next = root;
file_read_page(table_id, next, (page_t *)&c);
while (!c.header.is_leaf)
{
int i = 0;
while (i < c.header.num_of_keys && c.branch_factors[i].key <= key)
i++;
if (i == 0)
next = c.leftmost_index;
else
next = c.branch_factors[i - 1].page_num;
file_read_page(table_id, next, (page_t *)&c);
}
return next;
}
int db_scan(int64_t table_id, int64_t begin_key, int64_t end_key, std::vector _keys, std::vector *values, std::vector *val_sizes)
스캔 함수는 여러개의 연속된 레코드의 값을 싹다 가져오는 함수이다. 파라미터로 전달된 begin_key부터 end_key까지 값을 가져온다.
int db_scan(int64_t table_id, int64_t begin_key, int64_t end_key,
std::vector<int64_t> *keys, std::vector<char *> *values, std::vector<uint16_t> *val_sizes)
{
pagenum_t current_page_num = bpt::find_leaf(table_id, bpt::get_root_num(table_id), begin_key);
leaf_page_t current_page;
file_read_page(table_id, current_page_num, (page_t *)¤t_page);
int point;
for (int i = 0; i < current_page.header.num_of_keys; i++)
{
if (current_page.slots[i].key >= begin_key)
{
point = i;
break;
}
}
if(begin_key == end_key) { //나중에 추가한 부분
key->push_back(cur_key);
char value = (char*)malloc(sizeof(char) * 113);
memcpy(value, ((char *)¤t_page) + current_page.slots[point].offset, current_page.slots[point].size);
values->push_back(value);
val_sizes->push_back(current_page.slots[point].size);
return 0;
}
int64_t cur_key = current_page.slots[point].key;
while (cur_key <= end_key)
{
keys->push_back(cur_key);
char value[113];
memcpy(value, ((char *)¤t_page) + current_page.slots[point].offset, current_page.slots[point].size);
values->push_back(nullptr);
(*values)[values->size()-1] = (char*)malloc(sizeof(current_page.slots[point].size + 1));
memcpy((*values)[values->size() - 1], value, current_page.slots[point].size);
val_sizes->push_back(current_page.slots[point].size);
if (point == current_page.header.num_of_keys - 1)
{
current_page_num = current_page.right_sibling;
file_read_page(table_id, current_page_num, (page_t *)¤t_page);
point = 0;
}
else
{
point++;
}
cur_key = current_page.slots[point].key;
}
return 0;
}
scan함수는 find_leaf 함수로 begin_key가 포함되어있는 리프 페이지를 찾고, 그 안에서 begin_key 레코드의 slot 배열에서의 인덱스를 찾는다. 그리고 인덱스(point 변수)를 1씩 증가시키며 현재 키 값이 end_key보다 작거나 같을 때까지 값을 복사해온다.
스캔에서 실수하기 좋은 부분은
- 버스 에러 (값을 담는 배열을 잘 못 선언하여 스택 영역에 할당)
char value[112];
memcpy(value, ~, ~);
values->push_back(value);
이런식으로 값을 넣으면 안된다. 나는 처음에 아무 생각없이 이렇게 썼었는데, value를 담는 char 배열을 스택 영역에 선언해주고 푸시를 하면 함수를 나가면서 스택 영역에 잡혀있는 value[112]이 사라지기 때문에 나중에 vector안에 값에 직접 접근하려고 하면 버스에러가 떴었다.
그래서 반드시 malloc 또는 new 연산자를 이용해서 heap 영역에 할당을 해주어야한다.
-
begin_key == end_key인 경우 처음에 begin_key와 end_key가 같은 경우가 있음을 고려하지 못하고 코드를 짜서 저 경우에 무한루프가 돌았었다. 나의 경우, 그냥 begin_key == end_key인 경우에 해당 key 1개에 해당하는 value와 val_size만 복사해서 함수를 나가는 식으로 예외처리를 해줘서 해결했다.
1/7에 시작한 글을 1/15에 다썼다! 이걸 일주일 내내 쓴건 아니고 다른거 하느라 너무 바빴다..
아직 본격적인 과제 시작도 아닌 부분인데 꽤 오래 걸리네… 다음엔 insert에 대한 포스트를 써보려고 한다.
Leave a comment